
Psycho Clouds
This is a prototype to generate images from photograph of sky/clouds.
 |
The main pieces of this work are:
- Diffusion Model (StableDiffusion 2.1);
- ControlNet (by @thibaudz);
- Annotation methods (depth prediction and edge detections).
Background
Diffusion Model
Diffusion model is a generative model for images. Currently, is one of the most powerful deep learning architectures to generate high-quality images from prompts (i.e. text sentences). The model describes a Markov chain for noise removal process. This process is commonly called reverse diffusion process in order to recover the original image corrupted by the forward diffusion process which adds noise to the image.
The image below shows a forward diffusion process where we iteratively add noise to an image of a cat:
 |
At the beginning of the image generation, both the prompt and a random generated noised image are sent to the a latent space where measurements can be made between them. From now on, we will start to de-noise the representation of the noised image in the latent space (its embedding!). In simple terms, the prompt embedding guides the de-noising process of the noised embedding. The StableDiffusion model architecture is shown below:
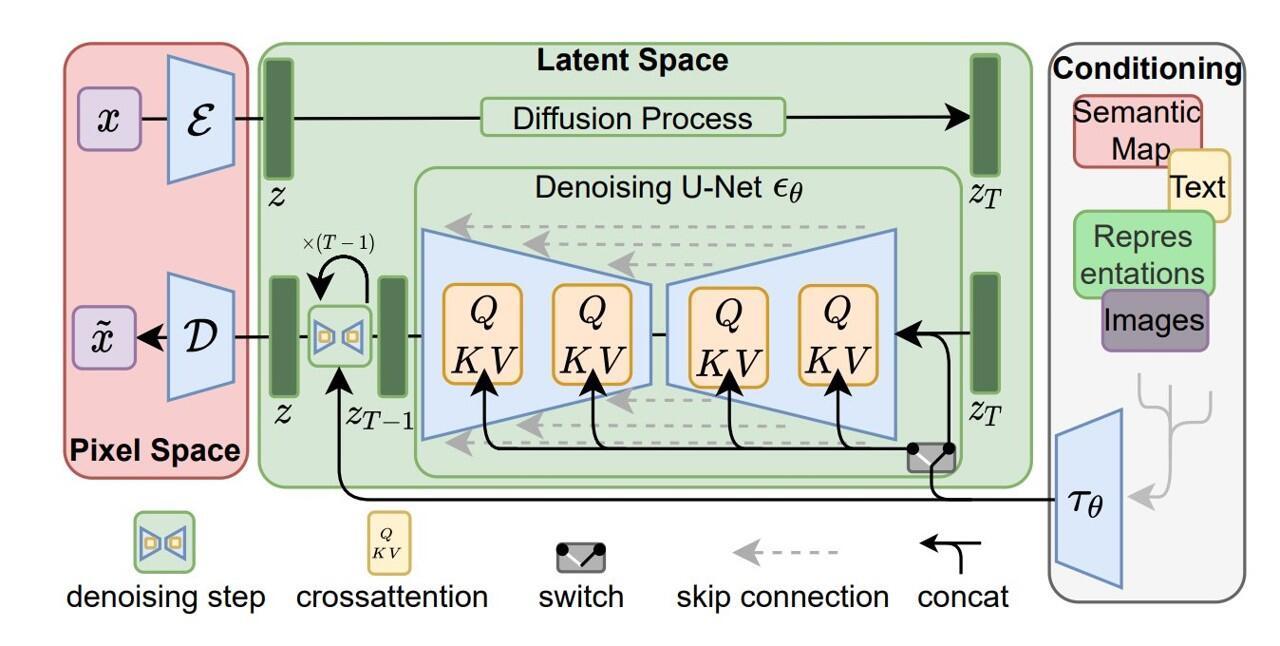 |
If you want to go deeper on the building blocks I recommend to take a look at some concepts: Attention Mechanisms (self and cross), Transformers, U-Net and ResNet. Specially this code implementing StableDiffusion model in single file.
ControlNet
Another key concept behind this work is ControlNet. ControlNet can be seen as an envelope for the diffusion model giving it more guidance capabilities (i.e. Control). Now, beside the prompt, we can get leverage of other images (i.e. annotations) helping to guide the noise removal seen above. There are available pre-trained ControlNet’s for many annotation methods out there like edge detections, segmentation, depth map, scribbles, poses, etc. See ControlNet repo for a complete list of available methods as of today.
A ControlNet is created by adding extra layers to the original diffusion model and fine-tunning them. At this point all generative capabilities of the diffusion model are preserved as only the extra guidance capability is added.
Many annotations can be used to guide image generation and may there will be others to come. Below some annotations commonly used for image generation:
 |
 |
 |
 |
| Original | Canny detection | HED detection | Depth map |
Pipeline
The pipeline below show briefly all steps of this work:
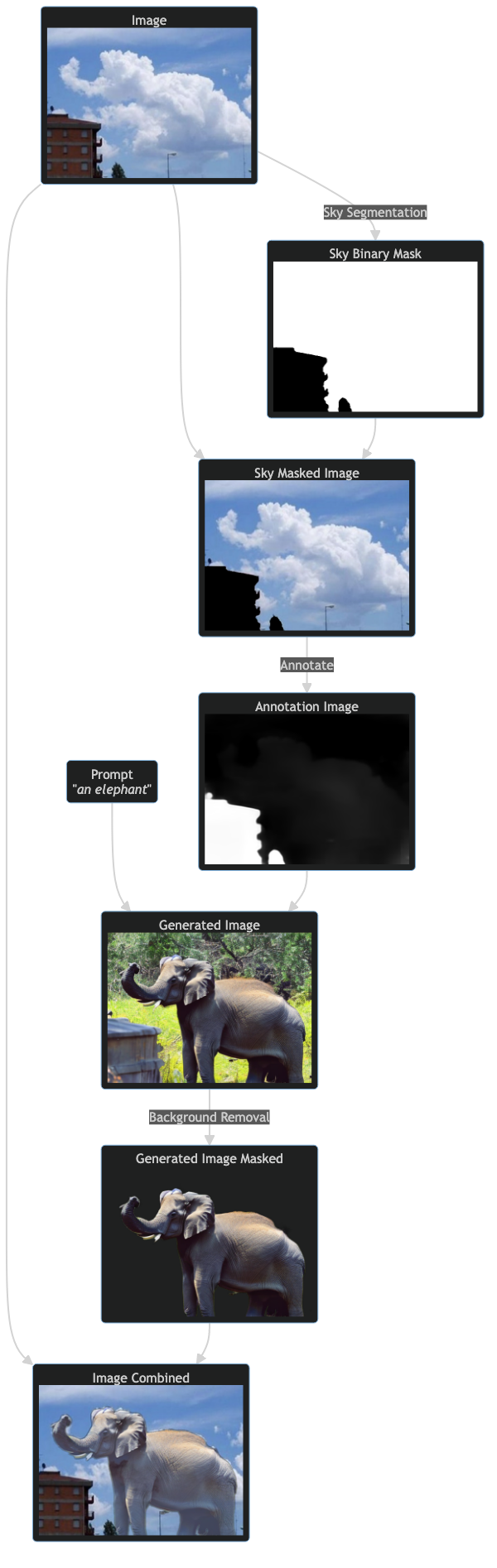 |
Results






Share
The notebook is available to be used, copied and modified. Enjoy: ![]()
Conclusion
The intent of this work is to be an introductory motivation for diffusion generative world and ControlNet.
There are a lot of improvements to be made in terms of optimizations and even reduce the pipeline. Feel free to contact me for further discussions. Thanks !